
The number of papers on COVID-19 grows so fast that nobody can really follow them all and stay up to date with the latest outcomes, not even the researchers. Having a tool that would allow them to quickly search for relevant papers could make their work a bit easier, but it could also prove useful to anyone looking for a reliable source of information on COVID-19. The good news is that a tool like this exists.
In this article, I’ll present to you our Natural Language Process (NLP)-based solution for automated COVID-19 papers analysis.
Why is efficient analysis of the COVID-19 papers so important? Well, they include a lot of insights which could save us not only from another pandemic, but also from many other civilization threats. Obviously the quicker the researchers get to them, the better for all of us.
Step 1: Finding a free resource for COVID-19 scientific papers
COVID-19 Open Research Dataset is a free resource delivering scientific papers, including full texts about COVID-19 and the coronavirus family of viruses, for use by the global research community. There is a Kaggle COVID-19 Open Research Dataset Challenge that uses this dataset as a base for looking for the answers to a series of important questions about the current pandemic.
For the purposes of this article, we are going to use the Open Research Dataset as our base, too, but our approach might be applied in many other domains — as long as there is a collection of texts to be analyzed.
Step 2: Understanding formal language and medical terminology
The main challenge that we face while designing such a tool is to find a way to easily compare the given question to the content of all of the gathered papers in order to select the ones that answer it. In other words, we need an effective method for finding papers relevant to our query. We can expect the papers to be written in a formal language, using some domain-specific words and phrases, and without the prior knowledge of the subject, we cannot really express our thought with exactly the same form as the researchers did. Our question may simply be written in a language so different from the language in the papers that the algorithm may have trouble finding answers.
That's where modern NLP methods come to the rescue.
Step 3: Selecting a method for text vectorization
Let’s find a good way of text vectorization. That is, a good way to transform text into a fixed-size vector. Then it can be easily compared with other texts in order to find the most similar ones.
There are plenty of algorithms to choose from, for example: Bag of Words, TFIDF, word2vec, or finally — BERT, which is thought to be the state-of-the-art method for text embeddings.
BERT-like vectorization
BERT is an NLP language representation method introduced by Google. It creates a contextual vector representation for the given text. As a result, unlike word2vec or GloVe, it doesn't operate on single word vectors, but a word can have different vectors depending on its context, that is — the neighbouring words. This way, this algorithm is able to encode more complex concepts.
A single word is a basic unit of text embeddings, and in order to encode whole sentences or paragraphs, we typically sum up the embeddings of all the words.
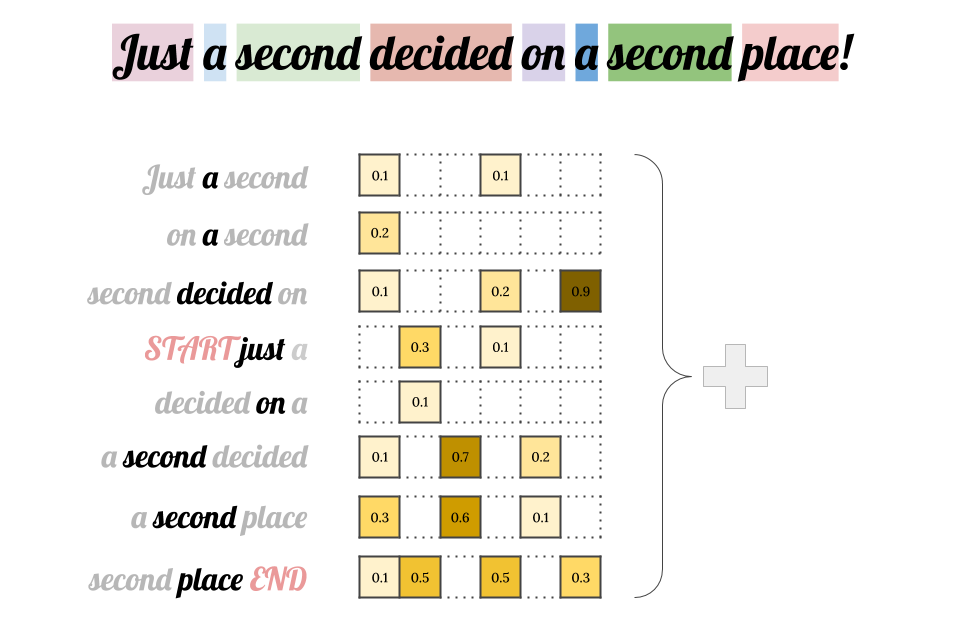
In the example above, the word “second” was used twice, but in completely different meanings, so there is no reason to have a single word embedding for both.
BERT is a model trained on language corpora for general purposes. It works pretty well for performing different domain-agnostic tasks. However, there are also plenty of extensions that use BERT-like modelling, but are trained on specific language subsets. Just to name a few:
- SciBERT - a BERT model for scientific text
- BioBERT - a pre-trained biomedical language representation model
- ClinicalBERT - a model for Clinical Notes modelling
- VideoBERT - a Joint Model for Video and Language Representation Learning
- PatentBERT - a model for patent classification
- DocBERT - a BERT model for document classification
In our research, we compared the “original” BERT with SciBERT to see how the training set affects the model’s performance. It seems that SciBERT generally gives better results for academic papers.
How to vectorize text with BERT
Creating an embedding vector for a given text with BERT is extremely easy. All we have to do is take a text, tokenize it, and insert it as an input into the network, then use a value of one of the hidden layers. To make things even simpler, there is a bert-as-service project that exposes the BERT functionality over TCP (internally ZeroMQ is being used).
Now, vectorization is possible within just 2 lines of code.
Step 4: Creating a BERT-based question answering system
Ideally, we should be able to ask a question and the system would automatically find the pieces of text which answer it. But if we just write in a question and vectorize it, then its representation will be similar to other questions, not to the answers. We need to find a way to go from question to answer, and it’s quite a complex issue.
There are three ways of handling it:
- We can create a dataset consisting of questions and answers to those questions marked in all texts. Then, the model will be trained to find the correct answers and we can hope it will generalize well. But this method requires both domain knowledge and a lot of time.
- Using known language rules, we can try to find a way to automatically convert a question to an affirmative sentence that could be the beginning of the answer. We can expect that all the answers will have similar vector representations, so finding them should be possible. It’s possible, but still time-consuming, isn’t it?
- Similarly to the method above - we can rewrite questions into affirmative sentences. And that’s what we are going to do!
Step 5: Et voilà! An example
So, using the third of the above-mentioned methods, we asked our newly created system if there is any research on successful attempts of COVID-19 treatment. The following text has been entered as an input:
“There is a promising treatment for COVID-19”
And here are the results:

These are the most similar paragraphs to our input phrase. The 4th point sounds like there might be some good news at last, doesn’t it?
Conclusion
New papers on the novel coronavirus and COVID-19 appear everyday, as scientists and doctors become more familiar with the disease. Laboratories around the globe are constantly carrying out research to understand the virus better and to develop the optimal treatment methods. The world is on its toes, waiting for a safe and effective vaccine. Automating COVID-19 papers analysis with Natural Language Processing may help to speed up the research process, but it may also give access to reliable insights to anyone interested in the subject.
If you would like to check out the source code behind the presented tool for automated papers analysis or play a little bit with your own examples, the full notebooks are available on our github: https://github.com/codete/coronavirus-papers-analysis.
If you need assistance with you NLP-projects, don't hesitate to contact Codete. We'll be happy to help!