

Chatbots are one of the solutions that are used for automation. Bots are used in many areas like fintech, e-commerce, government, and many others. Most chatbots use natural language processing methods and in many cases also machine learning methods. This article is an introduction to chatbots and can be helpful for everyone starting in chatbots.
In the first section, we show the differences between types of chatbots. Tools overview is given in the second section. Recommended ones are used in the third. The pipeline of building an intelligent chatbot is proposed and explained - so if you’re wondering how to build a chatbot in Python go straight to that part. Finally, we give a few recommendations and show the upcoming trends in chatbots development.
The rising significance of AI chatbots (Python-based especially)
A chatbot is a type of artificial intelligence (AI) software that can imitate a natural language interaction with a user via messaging apps, websites, mobile apps, or the telephone. It is frequently referred to as one of the most advanced and promising forms of human-machine interaction. However, from a technology standpoint, a chatbot is simply the natural progression of a Question Answering system that makes use of Natural Language Processing. One of the most common examples of NLP used in many enterprise end-use applications is formulating responses to inquiries in natural language.
Chatbot taxonomy
Chatbots can be divided into groups, depending on topics like complexity, usage, or privacy. The most popular taxonomy divides chatbots into three groups:
- rule-based chatbots,
- retrieval-based chatbots,
- generative-based chatbots.
The rule-based chatbots rely on a list of questions and corresponding answers. It can be a loose list of questions or a simple scenario with such questions where the user is asked questions one by one until the chatbot gets all information needed to return a valuable response. It could be a flight booking chatbot asking about the departure date, destination, and departure locations. After the response, the chatbot can ask more to filter the best fit like the number of stops, time of departure or arrival, and so on. It is simple and we don’t need to use any machine learning methods and in most cases, no natural language processing is needed. We can easily rely on regular expressions or in more advanced cases use string distance metrics that can surprisingly give good results in many cases.
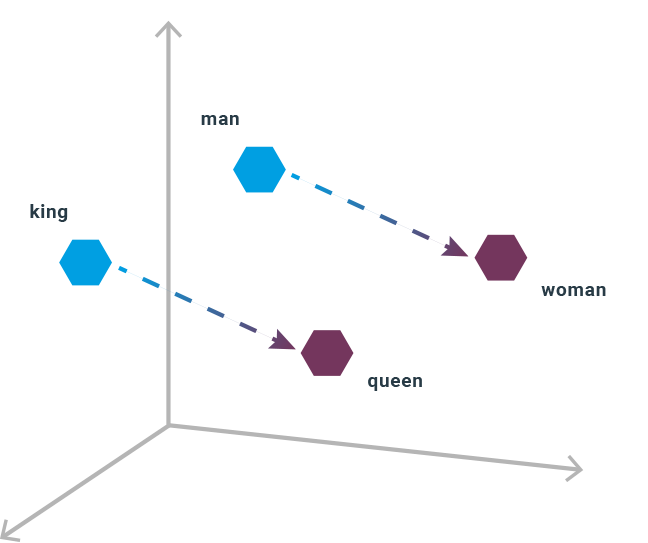
Retrieval-based chatbots rely on machine learning and word vectorization. Words are vectorized because machine learning methods use numbers for prediction. There are several methods that can be used for vectorization. The result of vectorization allows putting each word in a feature space. In many cases, the vector consists of more values. In SpaCy the vector for the most popular model is the size of 384. It can be reduced to a two- or three-dimensional space with t-SNE or similar methods. An example of a few words in a three-dimensional space is given in figure 1. We can easily apply mathematical operations to manipulate the data. Each word that is represented as a vector can next be used to train a model. In the case of retrieval-based chatbots, we train intent prediction. It means that we can discover users’ intent and based on that we can build scenarios of a conversation. When it comes to machine learning methods, no one method gives the best results and we should check several and compare which one gives the best results.
Generative-based chatbots are the most complex compared to the two previous approaches. It’s more generic, but the training requires a much bigger data set. This fact is in many cases a limitation for many companies. They cannot afford to get a big data set of examples for training. Generative-based chatbots use deep learning methods for training. If done properly, generative-based chatbots give impressive results.
There are many companies, especially in fintech, that are highly regulated or limited in a way that doesn’t allow sharing information outside of the company. In such a case, we cannot use tools like Dialogflow or any other that we cannot set up locally. Such conditions allow us to divide the chatbots into two groups:
- online,
- on-premise.
In other words, it divides the chatbots into ones that base on open-source tools only and chatbots that are based on any kind of tools. We can divide the chatbots also because of the role or domain. There are two simple types:
- superbots,
- domain-driven chatbots.
There are not so many superbots available to everyone. Google Assistant or Siri are good examples of superbots that cover many domains. Most companies focus on domain-driven chatbots that cover just one domain.
Available tools
Tools for chatbots can be divided into three types:
- NLU/NLP related tools that can help to understand the text,
- libraries and frameworks for building chatbots,
- API or online solutions that allow using tools that cannot be deployed locally.
In the first group, we have such classic libraries as NLTK or CoreNLP. Both are well-known by everyone who did something with NLP before. Currently, tools like SpaCy, TextBlob, and Gensim are more popular. Especially, the first one is trending and became the new first choice for NLP tasks.
The second group is libraries that can be used for chatbots directly like Rasa. It consists of a few subprojects which combined allow to build a retrieval-based chatbot with less effort. It is open-source and delivers a few predefined pipelines. It’s easier to train a model for intent prediction using Rasa.
The last group is probably the biggest one and consists of all online tools that allow to do some basic NLP/NLU analysis, use more advanced methods, and train chatbots. The most popular tools are delivered by Google, Microsoft, Facebook, and Amazon. Some allow to analyze the sentiment, other tools allow to build chatbot scenarios or build new skills or an already existing bot like Alexa. Dialogflow is a very similar solution to Rasa, but it’s not open source. We can build similar scenarios as in Rasa and feed them with examples for intent recognition. It can be done through a nice web interface.
Building intelligent chatbots - how to make a chatbot in python
Currently, most chatbots are retrieval-based. The goal here is to recognize the intent from the build scenarios. Intent recognition is just a supervised classifier that distinguishes between many classes (intents). The training phase needs a labeled data set with intents and example user input. It goes through the pipeline to finally get a model that can predict the intent. The topic of the NLP pipeline will be covered in a separate article. Finally, we get results as given in figure 2.

A separate part of the training is to train the scenarios where each intent is followed by several utters, the chatbot responses. Usually, many scenarios can be complementary or even overlap one another. To manage it appropriately, usually, a state machine is used, where the chatbot changes the state after each action is taken.
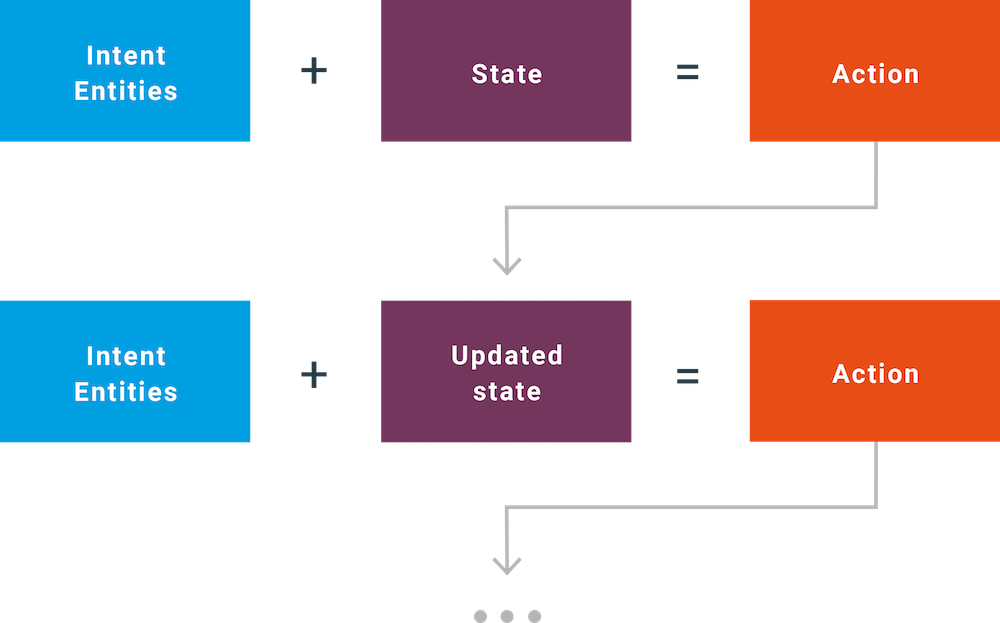
The action is invoked by the intent. What makes the chatbot intelligent is that it can give a different answer to the same intent/question, based on the current state. In other words, it remembers what the chatbot did earlier. An example is shown in figure 3.
Or, simply use the ChatterBot (Python library)
ChatterBot, as the name implies, is a Python library that is specifically built to construct chatbots - simplifying the development of conversational chatbots. This method employs a number of machine learning algorithms to generate a variety of responses for consumers based on their requests.
It begins with the creation of an untrained chatterbot with no past experience or knowledge of how to communicate. As users enter statements, the library retains the user's request as well as the responses that are delivered back to the users. As the number of instances in chatterbot grows, so does the accuracy of chatterbot's responses.
Chatterbot has been trained to look for the most similar analogous response by locating the most similar analogous request made by users that is equivalent to the new request submitted. Then it chooses a response from the list of pre-existing responses. Chatterbot's unique selling point is that it allows developers to easily design their own datasets and structures. If you want to see some code, there’s an excellent tutorial on how to build a chatbot in Python here.
Chatbot using python: Current trends
For a few years now, deep learning methods have been used more often also for chatbots. There are new neural network architectures that can have an important impact on chatbots development. Such an example is the attention network. Most papers at NIPS and ACL conferences do not directly talk about chatbots, but more about NLP methods that potentially can be used for chatbots. One of the popular topics which are recently discussed at such conferences is sentiment analysis, so we can expect an improvement in this area also for chatbots.
Upcoming trainings
We are proud to announce our upcoming online training on the Safari platform. There are two training sessions about chatbots scheduled for three hours each. Each consists of three exercises. The first one is on building intelligent chatbots in Python and will be held on March 7th. In the second we go through a sentiment analysis pipeline and show how to build your method of sentiment analysis.


References
[1] Designing Bots, 1st Edition, Amir Shevat. O’Reilly 2017
[2] Data Science from Scratch, Joel Grus. O’Reilly 2015
[3] Mining the Social Web, 3rd Edition, Mikhail Klasse and; Matthew A. Russell. O’Reilly 2019
[4] Natural Language Processing with Python, Edward Loper, Ewan Klein and Steven Bird. O’Reilly 2009