

Product recommender systems have been around since the beginning of e-commerce, and the use of machine learning & recommendation engine for products was just around the corner. First implementations kept recommending the same products for every user but thanks to the development of machine learning technologies that’s no longer the case.
Recommender systems have become so commonplace that many of us use them without even knowing it. Nowadays, users expect the apps, news sites, social media, and online stores they engage with to remember who they are, what they’re interested in, and make relevant, individualized, and accurate recommendations for them.
This helps users find what they are looking for and, sometimes, products that they don’t even realize they were looking for. In doing so, the business can learn more about each user’s preferences and interests, optimizing performance in real time and simultaneously refining their testing roadmaps for the long term.
Table of contents:
- Machine learning & recommendation engine in short
- Product recommendation system - features & strategies
- ML-based product recommendation systems - challenges
- Product recommendation using machine learning - wrap up
Machine learning & recommendation engine in short
But what machine learning & product recommendation is, in a nutshell, and what this combo can be used for?
A product recommendation software is simply a tool designed to generate and provide a specific user with a suggestion for an item or content which this user would like to purchase or engage with.
When it comes to the recommendation strategies there are three primary tiers:
- Global
- Contextual
- Personalized
Global recommendation strategies tend to be the easiest to implement. They simply serve any user the most frequently purchased, popular, or trending products. They can be implemented for both known and unknown users.
Contextual recommendation strategies rely on the product context, assessing product attributes, such as color, style, features that it offers, sub-category that it falls under, and how frequently it is purchased with other products, to recommend particular items to shoppers. They can also use data obtained from users’ product ratings and feedback, but these tend to be biased and lower in volume.
Personalized recommendation strategies are the most sophisticated of the tiers, and ones that can leverage machine learning techniques the most. Based on the collected data recommendation algorithm creates a net of complex connections between products and users.
If you want to build a recommendation engine, the first thing you need is data - data about the products offered (their specific features, prices, etc.), as well as data considering users. The more data is collected the better. Both demographic (age, location, weather, gender, etc.) and behavioral data is required to build a robust system.
The data can be gathered explicitly - i.e., users provide their demographic data when creating an account, or provide product data by leaving a review or rating for product - or implicitly. Implicit data is information that is not provided intentionally but rather derived from available metadata, such as search history, clicks, order history, time spent on browsing different products, and other activities.
When the data is collected and stored, it must be filtered to extract relevant information required to make a personalized recommendation.
Product recommendation system - features & strategies
Let’s now dive into the various recommendation strategies used by the top recommendation engine providers, breaking down their pros and cons, and when they should be used.
Top Item / Most Popular
One of the most widely used strategies is to show “top items” or items that are ranked as “highly purchased” or “best”. The ranking is obtained based on the weighted sum of interactions, such as purchases, add-to-cart, product views, and user ratings. The system favors recent interactions over historical ones and updates scoring periodically, as the data is fed into the system.
While this strategy isn’t based on highly personalized data, it may come in handy when little-to-no information is known about the user, or when the user’s behavior shows that they are just browsing around the site. It’s also useful when you want to promote your hottest items, helping your business to stand out against the competition.
User / Product affinity
Affinity-based systems (aka content-based filtering) allow marketers to make compelling product recommendations when and to whom it matters most. As users browse a given site, interacting with various products, they are exposed to many product attributes. Affinity-based recommender systems then use these interactions to identify user affinities and preferences, building rich, user affinity profiles for each visitor.
Affinity profiles are then used to provide personalized recommendations to each visitor. Each profile features a weighted score based on the correlation between user interactions (number of views, add-to-carts, purchases, etc.) and the attributes of the products users interacted with. The system then bases its recommendations on these scores and can work in real time, detecting any preference change. This strategy often takes the form of a “Recommended for you” widget.
Collaborative filtering
Collaborative filtering allows us to make product attributes abstract and make predictions based on user tastes. This method is based on the assumption that two users who liked the same products in the past will probably like the same ones now. Data about ratings or interactions can be represented as a set of matrices, with products and users as dimensions. The following two matrices are similar, but the second is deduced from the first by replacing existing ratings with the number one and missing ratings with the number zero. The resulting matrix is a truth table where number one represents an interaction of users with a product.
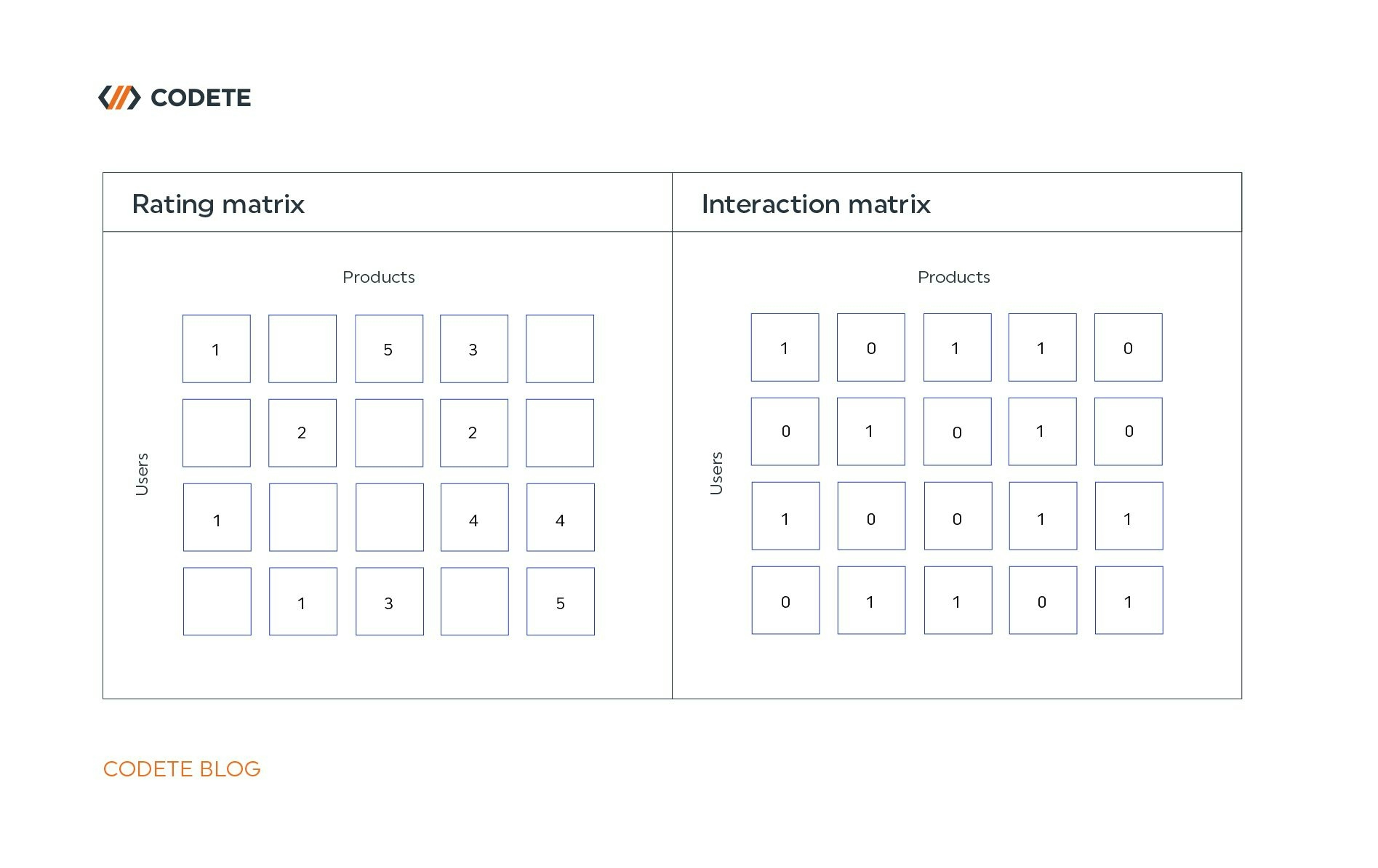
Based on similarity to other users, the system can make the most relevant recommendation. The algorithm most frequently used in collaborative filtering is k-nearest neighbors with cosine similarity or Euclidean distance used to determine neighbors.
Complementary filtering
In this case, the system learns the probability of two or more products being bought together. For example, when a user buys a smartphone from an eCommerce store, it is more probable that on the next visit this user will buy a pair of headphones or a smartphone case, rather than another smartphone.
As such, the algorithms are based on recommending products that will match other products. Meaning they are product-oriented, as opposed to user-oriented (like in collaborative filtering). The most used algorithm in such cases is Naïve Bayes.
ML-based product recommendation systems - challenges
Product recommendation with machine learning is a great idea to boost your sales and improve the user experience. However, when implementing such systems, you should keep in mind potential issues that you may face. The most common of those are listed below.
Cold start
There are two categories of the cold start problem - user cold start, and product cold start. The first one pertains to the fact that when a new user enters a website, the system has no information about their preferences. Similarly, new products have no reviews, ratings, or clicks so no recommendation can be made.
The solution to the user cold start involves applying a popularity-based strategy. In the early stages, trending products can be recommended to the user and the selection can be narrowed down based on contextual information - location, which site they came from, a device used, etc. After a few clicks, a piece of behavioral information can be utilized and the selection can be built from there.
Product cold start problems can be solved with content-based filtering. The product recommendation system can use metadata about new products and create recommendations from there.
Data sparsity
This problem arises from the fact that users will typically rate only a limited number of the available items. The result of that is a sparse user-item interaction matrix with insufficient data for identifying similar users or products. Combining collaborative filtering with Naïve Bayes is a solution to this problem.
Accuracy
Accuracy is measured as the product recommendation system’s ability to correctly predict the item preferences of each user. The highest accuracy is achieved by systems that make recommendations by both comparing the habits of similar users (Collaborative filtering) as well as by offering products that share characteristics with other highly-rated products (Content-Based filtering).
Scalability
Scalability is an especially challenging problem with large, real-world datasets used today. A recommendation system trained on a small dataset may fail to provide good recommendations on a bigger dataset. Also, some algorithms tend to be computationally expensive to run - the larger the dataset the longer it will take to make recommendations from it. Advanced, large-scale assessment methods are required to deal with both issues.
Diversity
Another challenge for recommendation systems is increasing diversity without compromising the precision of the system. While collaborative filtering typically uses nearest neighbor methods to identify items that similar users like, the inverted method can be used to achieve diversity. K-furthest neighbor algorithm seeks to identify less similar neighborhoods to create more diverse recommendations. This basically means that the system will recommend items disliked by the least similar people.
Product recommendation using machine learning - wrap up
Implementing a product recommender system is a great way to improve the overall user experience of your application and increase the probability that users will come back to your website next time they need to buy something. But online shopping is not the only area where it can be used - a similar approach can be found in news, social media, multimedia or even dating apps. That’s because product recommendation & machine learning tends to become more and more common and all-encompassing these days, and solutions where analytics is performed directly on log user data can be found there, too.
Choosing the right solution, e.g. a cutting-edge product recommendation algorithm, will surely impact the success of your business and the satisfaction of your customers. So, which recommender system should you use for your application? As always, there is no definite answer, and it strongly depends on the product you offer and the type of user you target.
And how do you find the widespread use of product recommendation systems? Do you think they are helpful and worth using or too challenging? Are there any other use cases of machine learning & recommendation engines you would single out?