

The growth of social media usage changed the world of marketing. Delivering content had never been so easy, as it is nowadays. Any information can spread across the World in less than seconds and it is important to recognize what’s going on with your product or brand as fast as possible. It is especially crucial if anything goes wrong, or when you want to check how people percept the things you do.
That’s why we believe, having continuous and fully automatic monitoring of social media is a must-have for all businesses, and sentiment is one of the most important factors to keep an eye on.
What is sentiment analysis?
"Emotion" doesn't usually come to mind when you think about Artificial Intelligence or Machine Learning. However, there is an entire field of research that uses AI to understand how people feel about any topic, including news, products, movies, and restaurants.
Sentiment analysis, being a part of the emotion AI, is a well-known Natural Language Processing (NLP) problem which goal is to determine whether a particular text is positive, negative, or neutral. It can be thought of as a simpler variant of emotion recognition, which the author felt while writing. The variety of emotions is richer what makes this issue harder to solve, but for our purposes sentiment is just enough.
How does sentiment analysis help you with monitoring your brand perception?
Sentiment analysis can be used for survey research, social media analysis, and tracking psychological trends. It uses NLP (or linguistic algorithms) to turn opinions into datasets by assigning values to positive, negative, or neutral texts, while machine learning analyses the valuated data to uncover meaningful trends over time.
Think about a program that scans thousands of articles, reviews, ratings, and social media posts to assess real-time sentiment changes for guests of a particular hotel. As a result, guest satisfaction can be constantly monitored and improved by aggregating and assessing reviews and ratings. Sounds practical, right?
Still, there are a few aspects to include, while conducting a thorough Sentiment Analysis on your dataset. First of all, there is a large amount of planning required. Do the brainwork and answer yourself the following questions:
- How can you ensure that the algorithms capture valuable information? Maybe the phraseology you're using isn’t appropriate?
- How can you use your findings to improve products, services, and experiences?
Let’s take a minute and try to conduct a Sentiment Analysis on a test database.
When considering the media to be monitored, Twitter was our first choice because it is widely used and allows us to automatically retrieve messages that include a specific phrase or hashtag. It is also a tool that people use to inform others about what is going on right now. Then it appears to be intended for real-time analytics.
From text messages to sentiment
Humans have a natural ability to recognize somebody’s else feelings and we are quite good at it. Most of us can also deal with irony and read between the lines. An automated system needs to somehow learn from provided examples and find a way how to map words of texts into the sentiment.
The thing is, our minds don’t rely on words only, but may consider some more subtle things. What we found interesting was the usage of emojis, which are direct indicators of somebody’s emotions and can help to improve recognition accuracy. That’s why we decided to pay more attention to them.
As machine learning models are usually mathematical, there is a need to somehow map the texts from letters into numbers. This is so-called vectorization and for our purposes, we’ve chosen TFIDF[1] vectorization which splits the text into words and assigns each word a weight, depending on its importance.
For the training phase, we collected publicly available datasets of tweets[2],[3] labeled with their sentiment. It turned out, the number of unique words across these datasets was higher than 250 000. That means each given text is mapped into 250 000-dimensional space. That was definitely too many, so we reduced the dimensionality with the great help of PCA[4] to 500. That speeds up the computation a lot. In our experiments, we compared different machine learning models, and Random Forest Classifier[5] won the competition, as it had the highest accuracy of all.
The results
Stanford CoreNLP[6] is a state-of-the-art library in the field of NLP, and initially, we wanted to use it for our content monitoring tool, but it had about 50% percent of accuracy, which was below our expectations. Stanford’s tool was rather designed to work with longer texts, usually grammatically correct, but as Twitter limits the length of the messages and its users does not care about the linguistic correctness, the ability to work properly, with the texts we had, decreased.
That was why we decided to create a solution, that fits our needs.
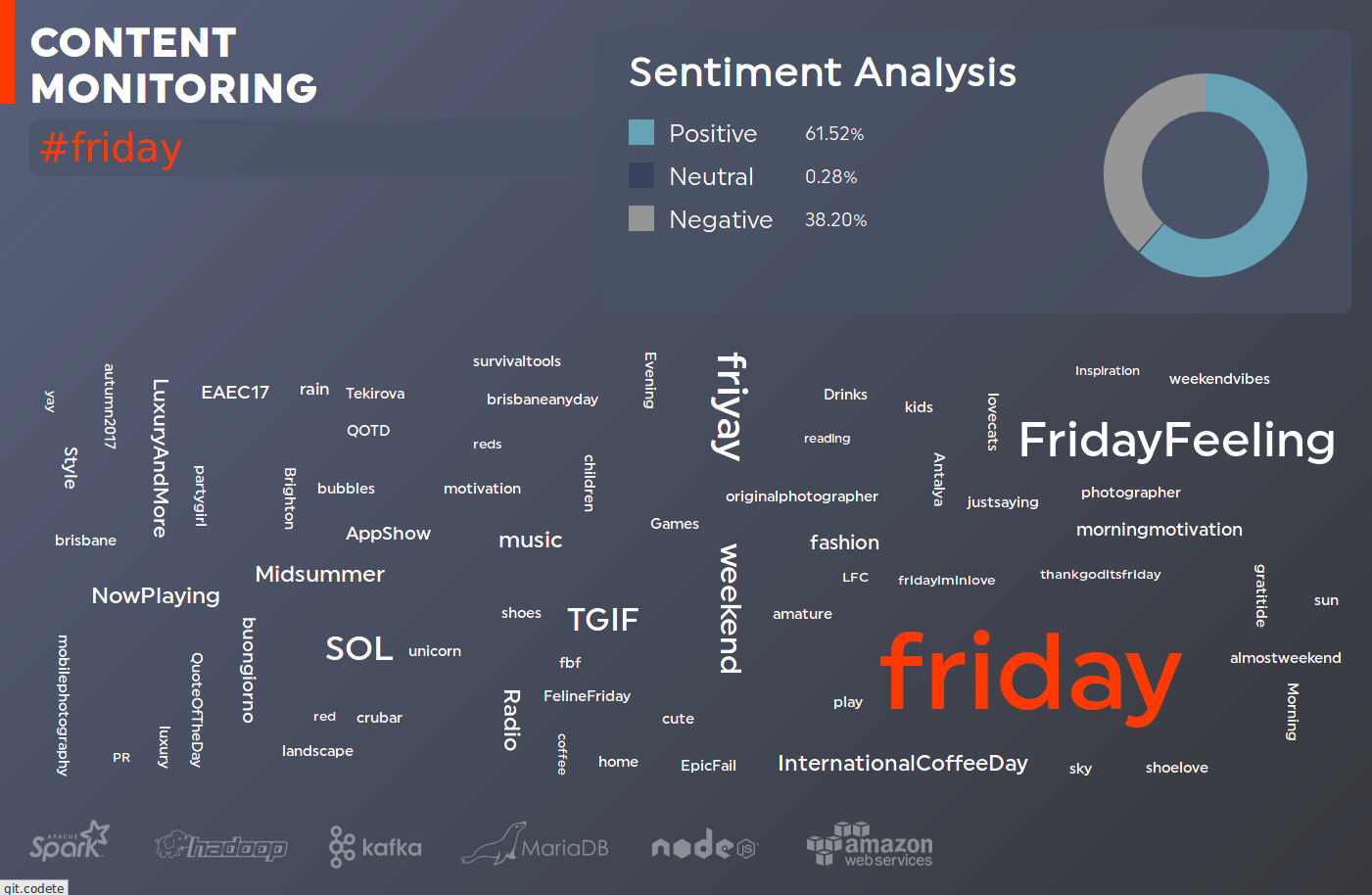
The described approach achieves accuracy higher than 75% on the same dataset like we tested Stanford CoreNLP on. Codete has created a tool that allows to put any input phrase, which will be monitored in Twitter, and to visualize the overall sentiment for all the matching tweets. It can be also used to perform the analytics of any brand perception.
Summary: emotion detection is (still) difficult
As a relatively new field, Emotion Detention techniques vary and mature. Traditionally, analysis has been done using what is known as a "bag of words" approach - by writing down a list of all the terms used, along with how many times they were used.
However, humans are complex and fascinating - and so are their opinions on different matters. In a perfect world, it’d be much easier if we could categorize responses with only one value. Still, the beauty of the language allows for adding a negative to a positive sentence (“their menu wasn't so bad”), context-switching sarcasm (“It was truly delicious. I’m overwhelmed with joy.”) or even stating something that’s not exactly real (“I wish their menu was tasty”).
As a result, "not bad" would come out as negative. Modern methods employ recurrent neural networks known as LSTMs (long short-term memory) to compress the entire phrase into a vector (a list of integers) that encapsulates the meaning of the sentence while taking word order into account. This has a better level of accuracy.
What does sentiment analysis mean for your business?
Analyzing each item of feedback by hand might be burdensome for firms that are invested in their consumers. Sentiment analysis created inside context can assist detect difficulties early and provide suggestions on how to enhance services.
Machine learning algorithms can process large volumes of data, learn and perform specialized tasks fast, and sift through data based on your objectives. As technology progresses, businesses may profit from these in-depth insights, and customer satisfaction will undoubtedly follow.
References:
- https://en.wikipedia.org/wiki/Tf%E2%80%93idf
- https://www.kaggle.com/crowdflower/twitter-airline-sentiment
- http://thinknook.com/twitter-sentiment-analysis-training-corpus-dataset-2012-09-22/
- https://en.wikipedia.org/wiki/Principal_component_analysis
- http://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html
- https://stanfordnlp.github.io/CoreNLP/